1 | # 停止docker |
参考链接
1 | # 停止docker |
参考链接
生命不息,折腾不止。在老家布置了一台服务器用于家庭影音中心,现在在新家,与老家相隔3000多公里,但是新家的服务器因为新装一无所有。此时此刻,突发奇想,我怎么能把老家的服务器里下载好的资源同步到新家的服务器上?
解决方案:
方案1直接pass。
方案2虽然也可以,但是群晖的连接好像直接复制到Aria2里下载不了,我可忍受不了下载一部50G的电影用浏览器自带的下载工具,而且还没有进度提示
方案3,emmmm……等有空再说
方案4,自己假设一台BT Trakcer服务器,然后做个种子下载,目前能想到的一个最佳方案
查阅相关资料,看看有没有现成的工具可以使用。
Searching …
!!!可以使用 OpenTracker 这个现成的工具来搭建。
那么问题来了,为了不搞乱服务器的环境,有没有现成的Docker镜像?
Continue searching …
在笔者孜孜不倦的努力下,真的发现了有人已经做好了镜像。
直接拉取镜像
1 | docker pull lednerb/opentracker-docker |
那么接下来如何启动一个容器?,我推荐docker-compose
1 | version: '3' |
当然你也可以直接
1 | docker run -dit --name opentracker -p 6969:6969/udp -p 6969:6969 lednerb/opentracker-docker |
好了。大功告成。
那么我怎么知道它运行了没有,怎么查看状态?
举个栗子,比如我假设在了yourhostname.com这台主机上,那么访问
1 | http://yourhostname.com:6969/state |
或者访问更详细的内容
1 | http://yourhostname.com:6969/state?mode=everything |
即可看到这家伙有没有在认真工作咯!
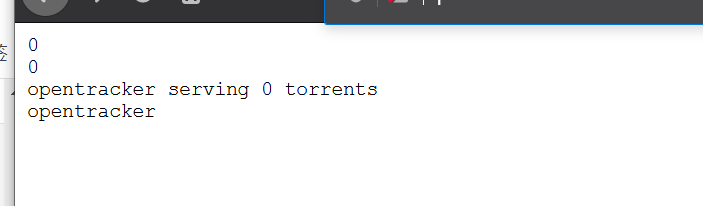
emmmmm…..刚搭建好,还没传种子。
我们创建一个种子,传上去试试看。
创建种子的时候Tracker服务器填:
1 | http://yourhostname.com:6969/announce |
或者
1 | udp://yourhostname.com:6969/announce |
在Transmission里看一下。。。

一切OK。。。
到后台看一下
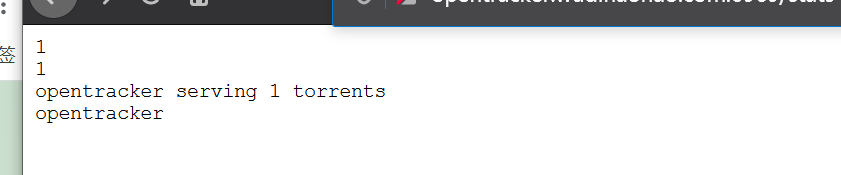
一切OK。。。可以看到已经增加了一个种子。
下载试试看。。
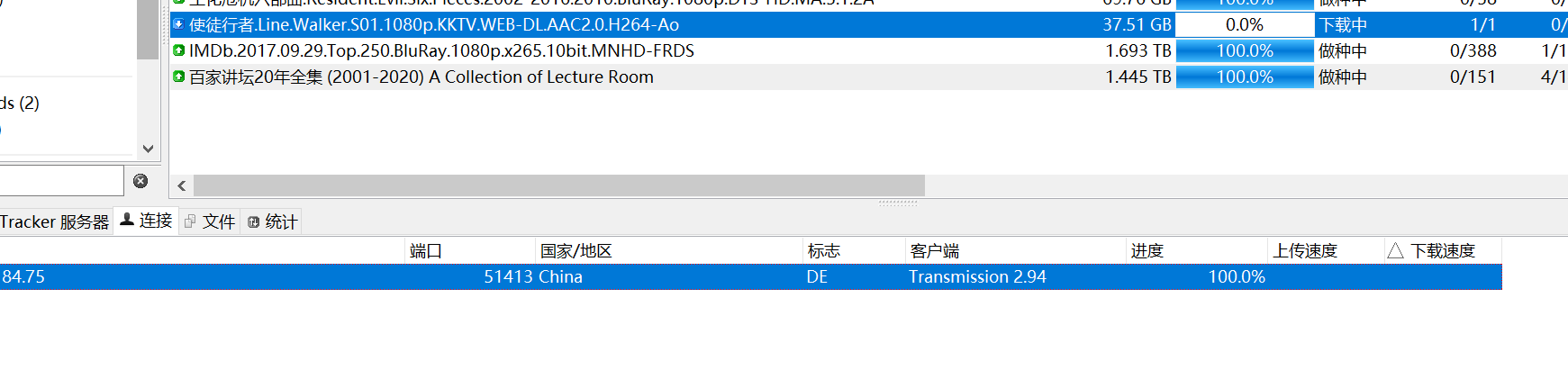
OK。。。已经出现一个peer了!
接下来就像下载BT一样,不过并不会有更多的peer出现,因为只有我自己在做种自己在下。。。
为了方便随时随地测试一些算法,做一些研究。笔者在自己的服务器上安装了jupyter-lab,这个是jupyter的下一代版本。但是因为不想搞乱自己服务器的环境,于是尝试寻找看看有没有jupyter的docker镜像,发现还真的有官方出的镜像。
官方出了很多镜像,根据不同的需求选择合适的镜像。本次搭建笔者选择了jupyter/datascience-notebook这个镜像,具体镜像列表参考:
https://jupyter-docker-stacks.readthedocs.io/en/latest/using/selecting.html
拉取镜像
1 | docker pull jupyter/datascience-notebook |
运行一个容器
1 | docker run -p 8888:8888 jupyter/datascience-notebook |
1 | root@ubuntu:~# docker run -p 8888:8888 jupyter/datascience-notebook |
访问你部署docker的那台主机,例如本次我部署在jupyter.local这台主机上,我们访问http://jupyter.local:8888会看到如下界面。
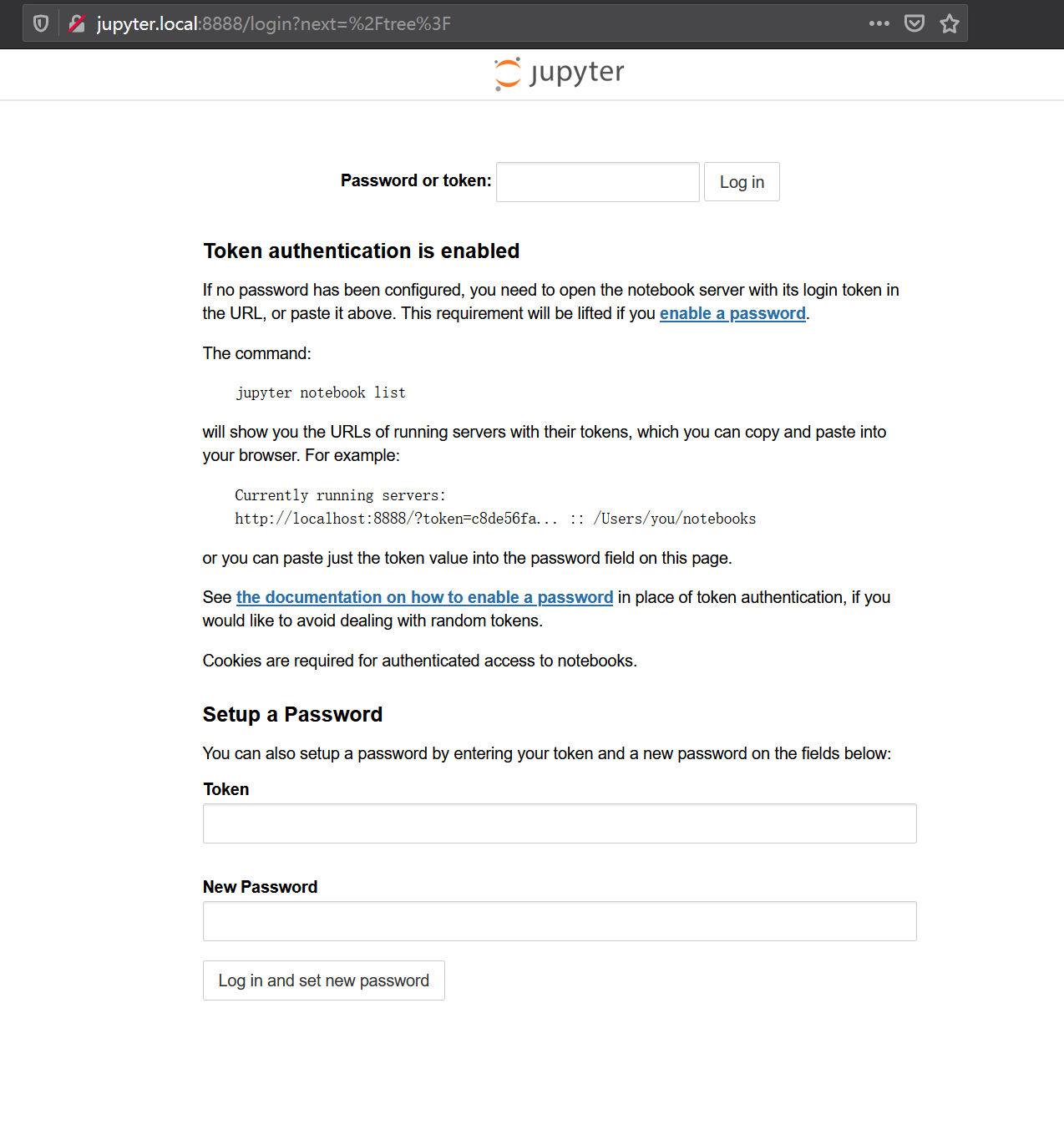
你可以使用token登录或使用token设置一个新密码。本次的token为2f725d16b757283384db037ff1707b590eca49d9ac037f3b
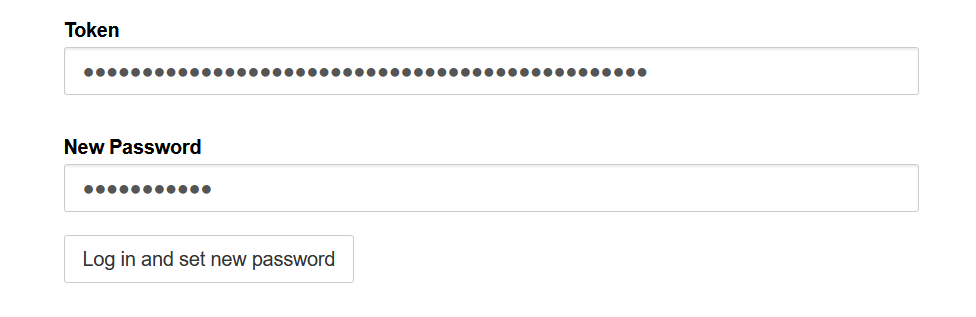
用token设置一个新密码然后登录。
这样就进来了。
但是这样我们的所有工作都在这个容器里,没有挂载外部的数据卷进来,当容器消失后我们的工作内容也将烟消云散。所以我们需要挂载外部的数据卷进来。
这里推荐使用docker-compose来启动容器,yaml格式的语法阅读非常清晰。
ubuntu 可以使用以下命令安装
1 | apt install docker-compose -y |
这里我们来看一个 docker compose 模板
1 | version: "3.1" |
在当前目录下新建一个work目录, 我们把这个目录挂载到容器里。JUPYTER_ENABLE_LAB=yes启用jupyter-lab,这个是jupyter的下一代版本。
1 | root@ubuntu:/home/naonao# mkdir work |
例如我在/home/naonao这个目录下新建一个work文件夹,然后再本目录下创建一个docker-compose.yaml文件,复制上面的内容进去。
运行容器
1 | docker-compose up |
1 | root@ubuntu:/home/naonao# nano docker-compose.yaml |
同刚才一样,你可以用token设置一个密码,或者也可以直接访问连接http://jupyter.local:8888/?token=a37dc92a50b7b6f3fb0f01abfee6a374b5fb74d23a0a3114,这里注意访问你部署docker的主机的地址,本例我部署在jupyter.local主机。我们将看到jupyer-lab的界面。
进入/work目录新建一个文件。
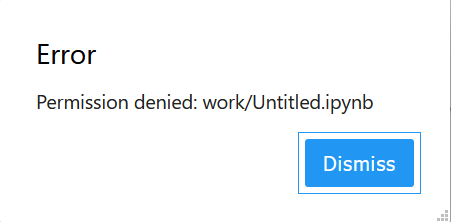
我的得到了一个Permission denied错误。
查阅资料发现
1 | You must grant the within-container notebook user or group (NB_UID or NB_GID) write access to the host directory (e.g., sudo chown 1000 /some/host/folder/for/work). |
https://jupyter-docker-stacks.readthedocs.io/en/latest/using/common.html
你必须允许容器的用户或组写你设置的这个目录
例如我挂载目录/home/naonao/work到容器里, 那么我需要更改这个目录的权限.chown 1000 /home/naonao/work
重启容器,问题解决。
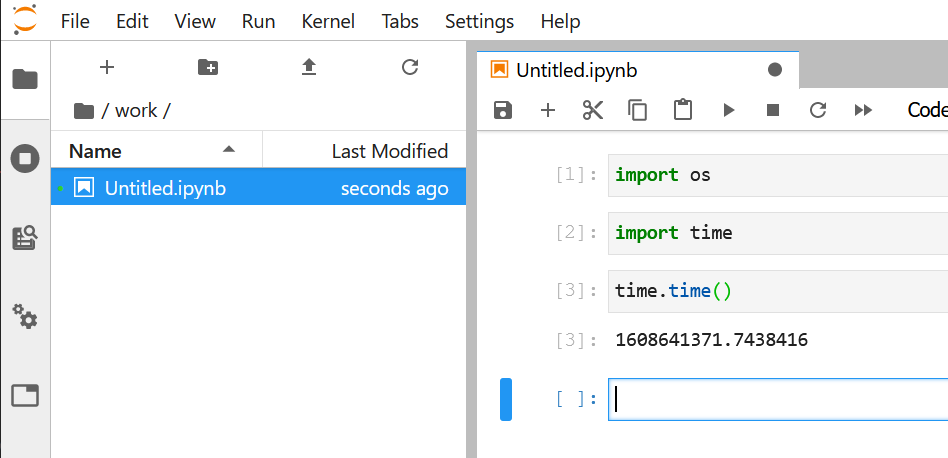
1 | root@ubuntu:/home/naonao# cd work |
如果把它架设在公共云上,那么我们可以通过域名在任意位置访问到jupyter环境。
通过Nginx反向代理并使用SSL加密HTTP
笔者用宝塔新建了一个静态网站,并设置了Let’s Encrpyt证书。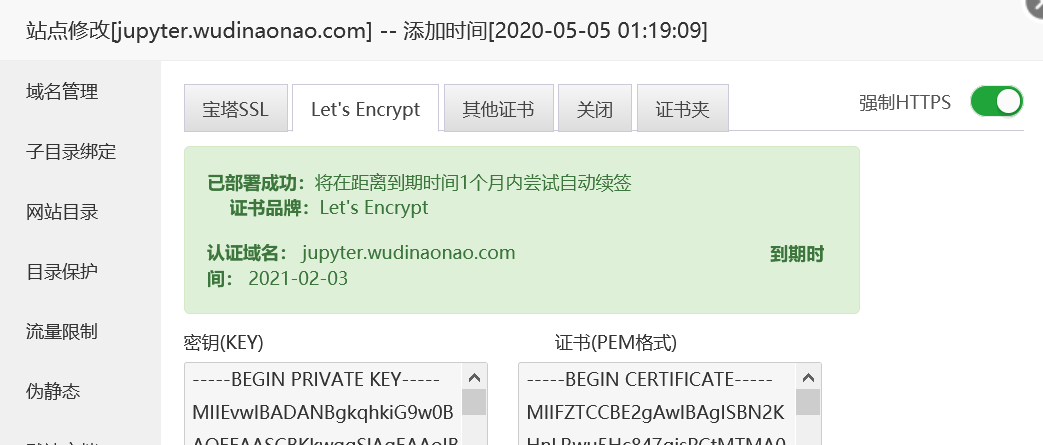
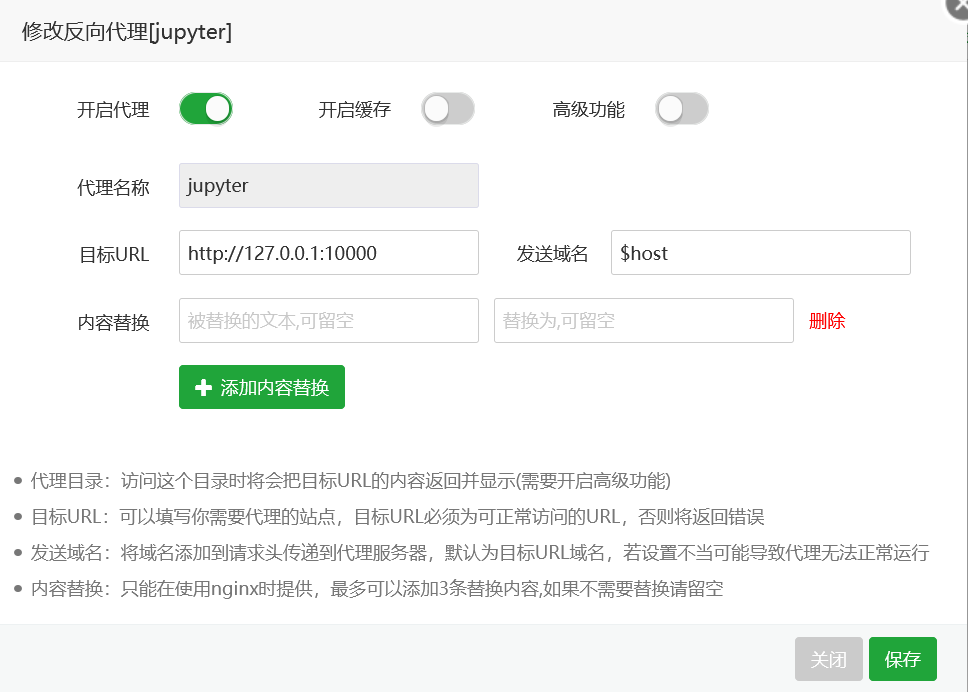
在华为云上部署docker,因为8888端口被占用,所以本次使用10000端口,在宝塔面板添加一个反向代理,当然你也可以自己配置Nginx。
完成单击配置文件
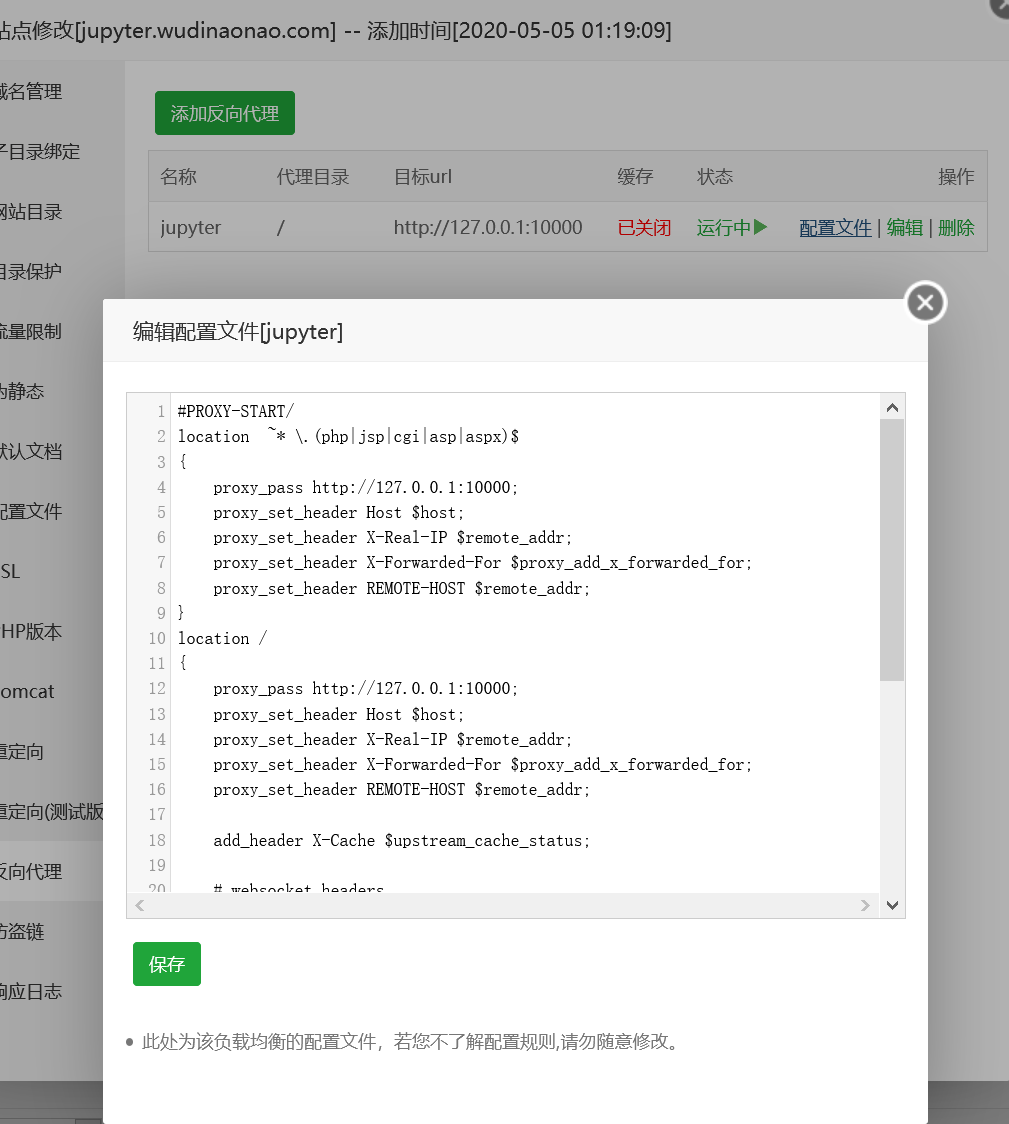
增加websocket
1 | # websocket headers |
然后在点击左边目录的配置文件增加
1 | map $http_upgrade $connection_upgrade { |
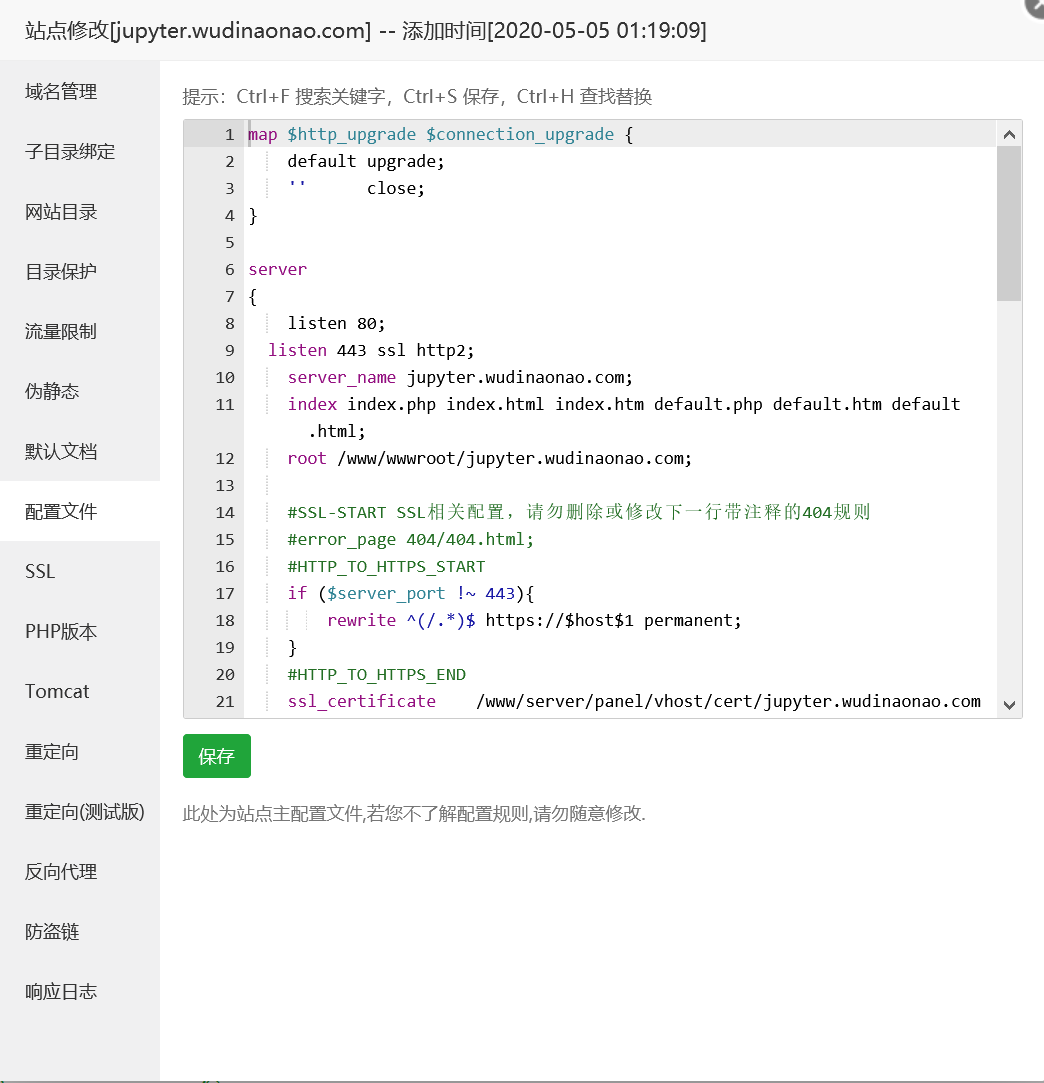
保存。
访问https://jupyter.wudinaonao.com一切正常
有时候通过Nginx反向代理会出现可以访问界面但是无法连接到python,这是因为没有配置websocket导致。
通常出现在这种情况下,用户通过HTTPS访问Nginx的反向代理。即
user —https—> nginx —http—> docker
https://jupyter-docker-stacks.readthedocs.io/en/latest/using/selecting.html
https://jupyterhub.readthedocs.io/en/stable/reference/config-proxy.html
1 |
|
https://devopsheaven.com/docker/dockerhub/2018/04/09/delete-docker-image-tag-dockerhub.html
装饰器实现
1 | # 装饰器实现 |
元类实现
1 | # 元类实现 |
工厂模式属于创建型模式, 它提供了一种创建对象的最佳方式.
在工厂模式中, 我们在创建对象时不会对客户端暴露创建逻辑, 并且时通过使用一个共同的接口来指向新创建的对象.
1 | # 根据品牌名生产不同的汽车 |
当对象需要多个部分组合起来一步步创建,并且创建和表示分离的时候。可以这么理解,你要买电脑,工厂模式直接返回一个你需要型号的电脑,但是构造模式允许你自定义电脑各种配置类型,组装完成后给你。这个过程你可以传入builder从而自定义创建的方式。
假如我们要生产一台Computer, 我们需要首先定义一个Computer类, 他表示了一个Computer由那些组件组成. 然后定义一个Builer, Builer用于组装Computer. 最后定义一个Enginner, 工程师告诉Builer用那些配件参数生产Computer, 然后得到一台根据具体参数生产的Computer
1 | # 首先我们先定义一个 Computer 类 |
可以使用Python内置的copy模块实现. 拷贝分为深拷贝和浅拷贝, 这里我觉得有点像C里面的指针. 浅拷贝相当于复制了对象的指针, 还是指向同一个对象, 而深拷贝则完全复制了一个新的对象.
深拷贝的优点是对象之间完全独立互不影响, 但是这个操作会比较消耗资源.
浅拷贝的优点是仅仅复制了指向对象的指针, 因为引用的都是同一个对象, 这个操作比深拷贝消耗的资源要少得多, 但是因为指向同一个对象, 所以当对象需要进行某些操作时候要慎重考虑.
1 | import json |
未完待续…
这样定义的属性是类属性, 我们 new 两个实例测试下
1 | class MyClass(object): |
可以看到指向了相同的地址
1 | 2078100290056 |
再 __init__ 方法中创建的属性是实例属性
1 | class MyClass(object): |
可以看到指向了不同的地址
1 | 1631300614792 |
类属性属于类所有, 所有实例共享一个属性
实例属性属于实例所有, 每个实例各自独享一个属性
不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017594591051072
表名: table_name
查询列: column_name
1 | select * from table_name |
1 | select * from table_name as t1 |
表名: table_name
查询列: column_name
1 | delete from table_name |
1 | delete from table_name |
查看日志
1 | docker logs container_name_or_id |
Docker 日志目录
1 | /var/lib/docker/containers/container_id |
1 | v2ray: |
日志被限制在5g大小.
增加项文件
1 | { |
到文件, 如果没有则新建.
1 | /etc/docker/daemon.json |
重启docker
1 | service docker restart |
1 | e66515c..389e67f master -> gitlab/master |
放弃本地修改,直接覆盖
1 | git reset --hard |