Excel 中日期可能显示错误

显示成
1 | ###### |
这样, 如果你已经设置了单元格的日期格式, 那么就很有可能是列宽不够, 调整列宽, 即可正确显示

Excel 中日期可能显示错误
显示成
1 | ###### |
这样, 如果你已经设置了单元格的日期格式, 那么就很有可能是列宽不够, 调整列宽, 即可正确显示
2023年5月3日我更换了新的路由设备后出现了某些设备只能单向ping通的问题
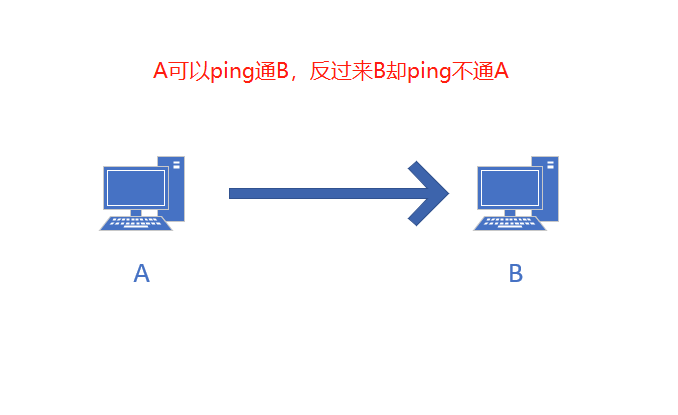
在同一个网段里,A可以ping通B,反过来Bping不通A。
ping命令基于ICMP协议,通常用于判断数据包是否能通过IP协议到达目的主机
抓包看看正常的ping
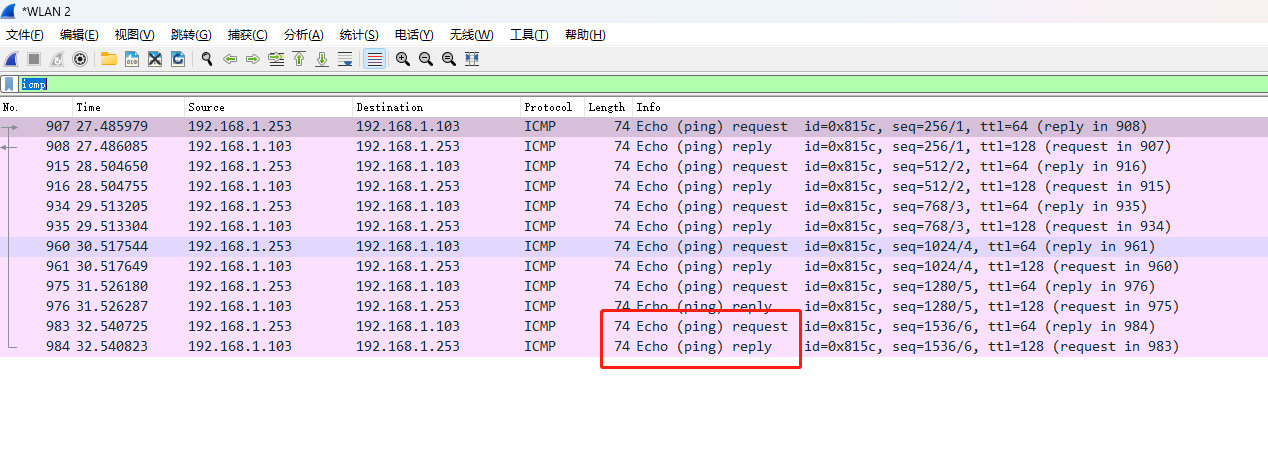
我们将 192.168.1.253 这台主机记作 A,192.168.1.103 这台主机记作B
可以看到 A 先发送了一个 request 包,然后 B 回复了一个 reply 包,从此 A -> B 之间的链路是通的。
但是会出现一种问题,A -> B 通,反过来 B -> A 不通!
通常出现单向 ping 通的原因有以下几点:
开启了防火墙
一般的做法是将来自外部的ICMP请求报文滤掉,但它却对本机出去的ICMP请求报文,以及来自外部的ICMP应答报文不加任何限制。这样,从本机Ping其他机器时,如果网络正常,就没有问题。但如果从其他机器Ping这台机器,即使网络一切正常,也会出现“超时无应答”的错误。
设置了错误的IP地址
如果该主机上存在多块网卡,恰巧又将其设置成了同一个子网,那么从IP层协议来看,该主机就有多个不同的接口处于同一个网段内,当从该主机Ping其他主机时,就会存在如下问题:
本人遇到的问题是如下:
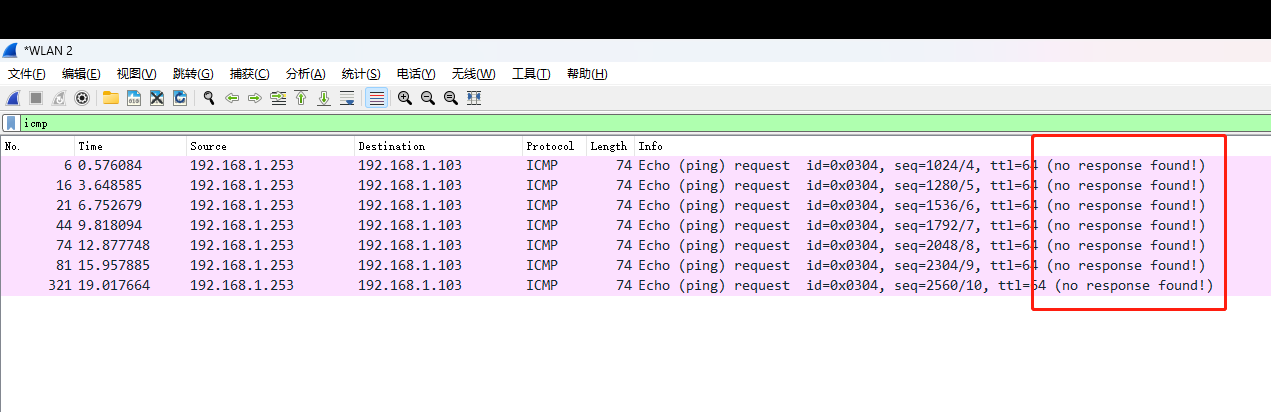
正常能收到 request 包,但是却没有进行任何回复,no response found!
这个问题困惑了我们很长时间,首先一方能ping通,说明链路是通的,交换机设置也没问题,那为什么另一方却ping不通?直到后来,我仔细的复盘的了一下出现问题的主机,我发现ping不通的,都是一些windows主机,linux主机完全没有这些问题。
可问题是,windows主机之前一直可以ping通啊,我没有改过任何防火墙的设置!
死马当活马医,尝试更改下windows防火墙设置,以管理员权限运行命令行,输入下面允许ICMPv4的命令
允许ICMPv4
1 | netsh advfirewall firewall add rule name="ICMP Allow incoming V4 echo request" protocol=icmpv4:8,any dir=in action=allow |
同理,拒绝ICMPv4 可以这么写
1 | netsh advfirewall firewall add rule name="ICMP Allow incoming V4 echo request" protocol=icmpv4:8,any dir=in action=block |
您猜怎么着?然后就好了!可以ping通了!
但是!但是!但是!windows主机之前一直是可以ping通的,为什么突然现在不行了,而且我没有改过任何windows防火墙的设置。
我思前想后,只有一种可能,windows的某个更新,将ping默认设置为禁止了!
但是我搜索了一下,却发现没有任何这方面的信息。
想想之前windows更新不经常是补了这个窟窿那边又捅了一个出来吗!也能理解!
不过好在现在问题解决了,是windows防火墙的原因!
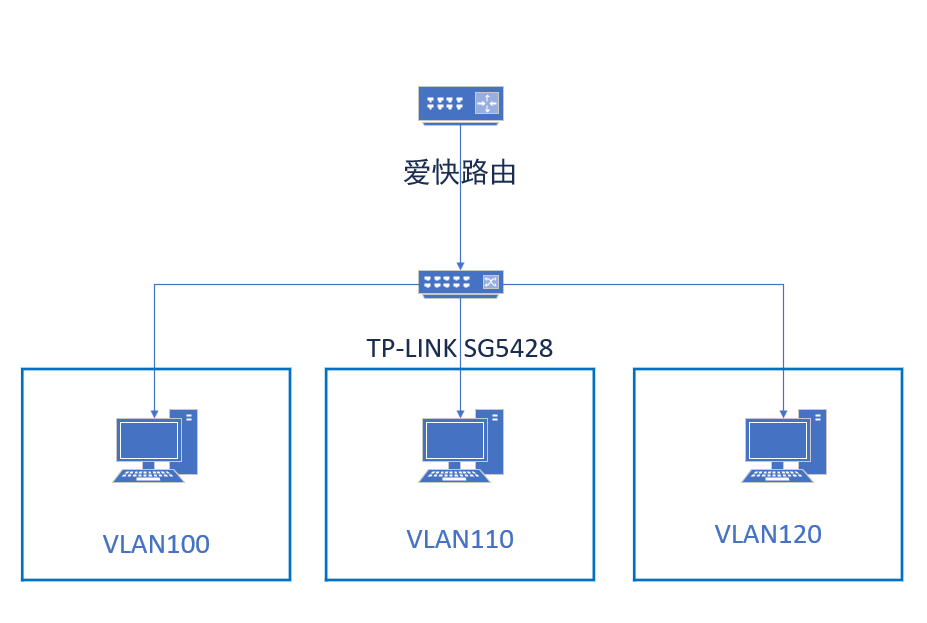
在这个网络拓扑下,如果我们使用爱快来提供DHCP服务,就需要在SG5428中配置DHCP中继服务。因为VLAN划分隔离了广播域,DHCP是一种广播报文,如果未经配置,从PC端发出的DHCP Discover 报文爱快则无法收到。
从SG5428说明书上找了一张报文交换过程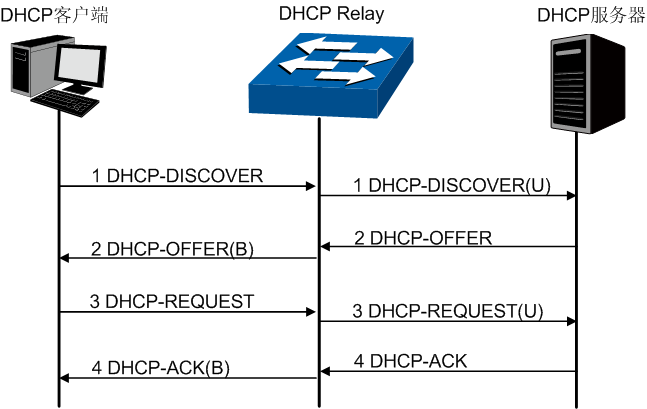
原理也很简单,接下来我们开始配置
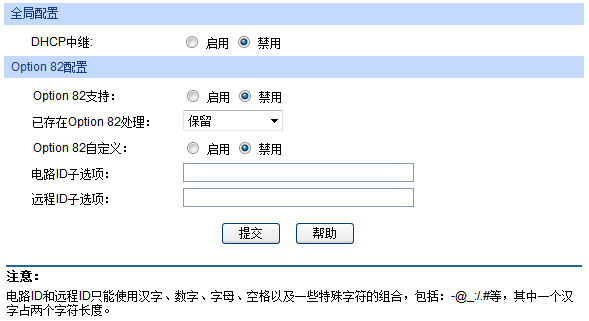
在全局配置中启用DHCP中继,Option82支持可以按需选择,我这里保持默认
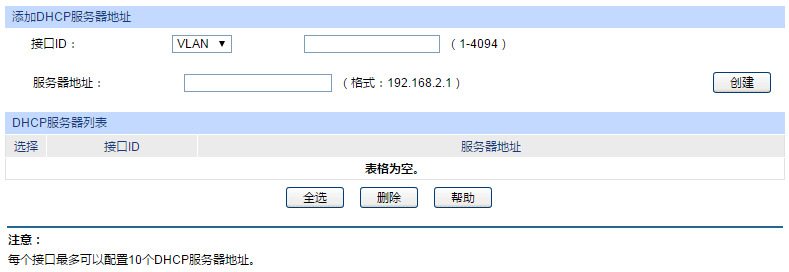
接下来将对应的接口ID,我们这里是,分别是VLAN100,VLAN110,VLAN120
服务器地址填写爱快的地址,然后点击创建即可完成DHCP中继。
注意,如果交换机开启了DHCP中继则需要关闭DHCP服务器功能
我们设置 VLAN100 的 DHCP
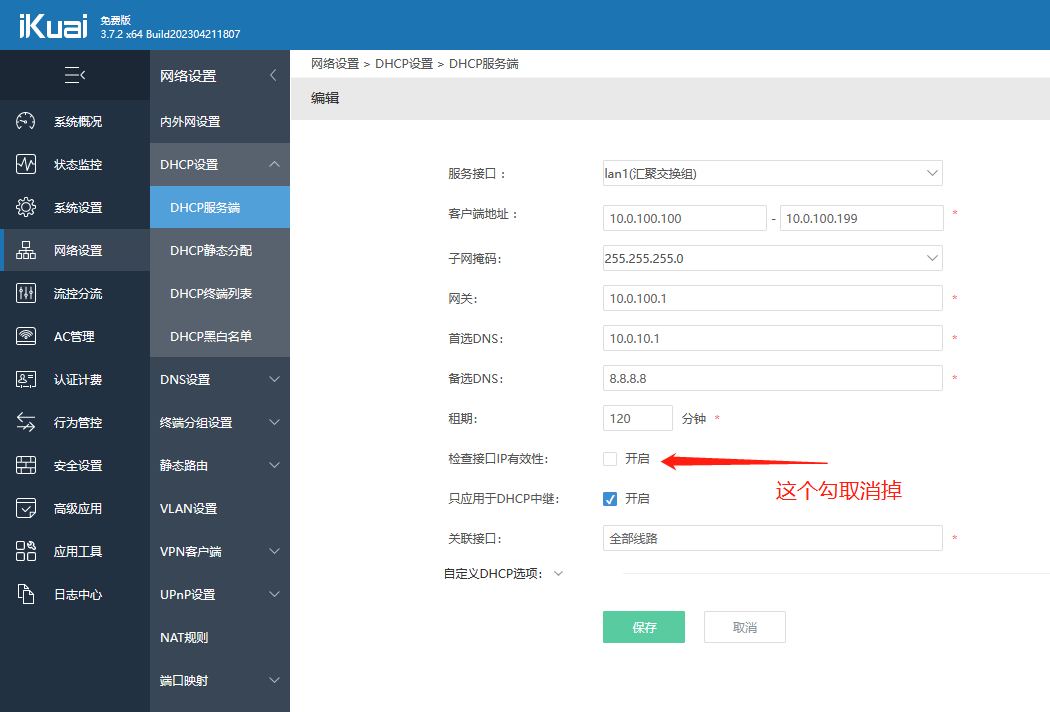
参考上述设置,将剩下的VLAN110,VLAN120设置保存
配置完毕后,按道理我们就可以使用爱快来提供DHCP服务了,但是我们发现PC端并没有获取到正确的IP。
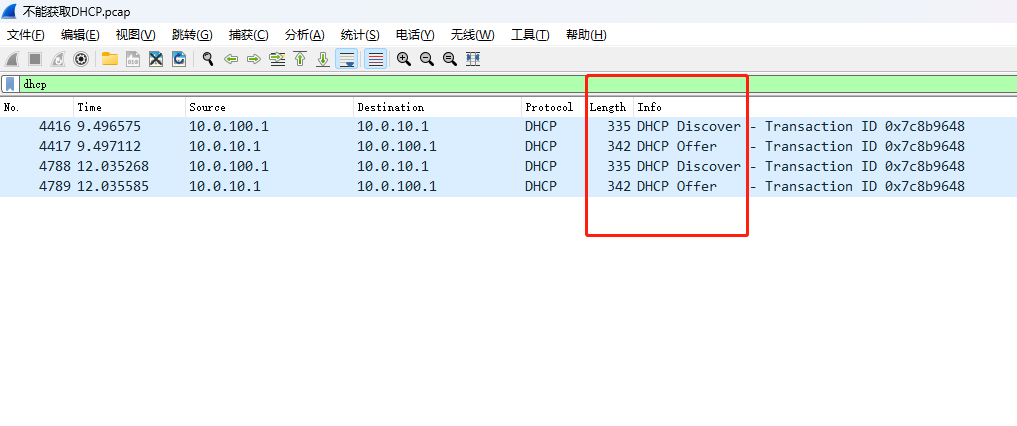
抓包后分析发现,爱快收到了 DHCP Discover 报文,并且也返回了一个 Offer 报文,但是却没有收到 PC 端后续的 Request 报文,该报文似乎被丢弃或屏蔽了。
我在这里耽搁了很久,一直没有很好的思路,直到我突然看到了我好像开启了全部的DOS攻击防护。
那么有没有一种可能,Request 报文被当作某种攻击给过滤了?
先尝试将DOS攻击防护全部禁用,重试果然可以获取到正确的IP了。
那么,到底是什么类型的防护把 DHCP Request 报文过滤掉了?
我依次将防护类型关闭打开,最后定位到是Blat Attack该类型的防护会过滤掉 DHCP Request 报文。
那么什么是 Blat Attack?
在Google搜了下,发现关于他的资料非常稀少,交换机用户手册上介绍
1 | 数据包的 L4 源端口等于目的端口且 URG 置位。此攻击方式类似于 |
该类型的攻击方式与 Land Attack 非常相似。
简单来讲,就是允许设备接受并响应来自网络、却宣称来自于设备自身的数据包,导致循环应答。
但是这个和 DHCP Request 报文有什么关系,限于笔者能力,暂时没有深入分析,也许是一个系统设计上的BUG?
因为我在Google没有找到任何该攻击方式影响 DHCP Request 报文的信息。
┑( ̄Д  ̄)┍
所有综上,把Blat Attack关闭 DHCP 中继即可正常使用
提示磁盘错误, 例如:
1 | "sata0:0"的磁盘类型 7 不受支持或无效。请确保磁盘已导入 |
可以通过如下命令来转换磁盘文件来解决
1 | vmkfstools -i <HostedVirtualDisk> <ESXVirtualDisk> |
如果是Windows的话可以直接使用软件StarWind V2V Converter转换
首先开启ESXI的SSH功能, 然后登陆进去, 找到目标磁盘文件
假设我们要转换的磁盘文件为
1 | openwrt-21.02.1-2022042317-x86-64-generic-squashfs-combined-efi.vmdk |
我们执行命令
1 | vmkfstools -i openwrt-21.02.1-2022042317-x86-64-generic-squashfs-combined-efi.vmdk new.vmdk |
会生成一个新的磁盘文件, 将新的磁盘文件挂载到虚拟机启动即可.
存在一种情况, 在第一启动的时候可以进行配置和保存, 但是重启之后, 配置无法保存, 表现为 /dev/root 这个目录变成了只读模式 Read-only file system
具体来讲就是从现在开始, 你的任何配置都无法保存了, 将在重启后被重置.
临时的解决方式
1 | mount -o remount rw / |
每次重启都需要执行, 你可以将这个命令写到
1 | /etc/rc.local |
文件里来开机自动执行.
但这终究不是一个合理的解决方式.
仔细定位问题后发现block-mount和这个模块有关.
查阅相关资料后, 我们可以在编译固件的时候不要编译该模块即可解决问题.
具体操作, make menuconfig 调出配置, 依次取消以下勾选
1 | Extra packages ---> automount |
重新编译即可解决.
首先安装这个工具
1 | apt install cifs-utils |
不然之后会提示
1 | (for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount. helper program) |
创建一个凭证文件, 可以放在任何位置 e.g.
1 | nano /etc/sambapin |
文件内容为
1 | username=xxx |
根据相关的字段填写对应的值,domain可以填写DOMAIN
e.g.
1 | username=admin |
然后编辑/etc/fstab新增一行
1 | //172.16.100.5/Downloads /home/download/Downloads cifs credentials=/etc/sambapin 0 0 |
表示将//172.16.100.5/Downloads这个目录挂载到本地的/home/download/Downloads上
如果出现错误提示
1 | mount error(95): Operation not supported |
有可能的原因是需要设置协议版本
1 | //172.16.100.5/Downloads /home/download/Downloads cifs credentials=/etc/sambapin,vers=1.0 0 0 |
如上, 在credentials=/etc/sambapin后加上协议版本即可
https://www.truenas.com/community/threads/mounting-smb-with-ubuntu-mount-error-95.71137/
https://askubuntu.com/questions/525243/why-do-i-get-wrong-fs-type-bad-option-bad-superblock-error
容器仓库是容器化管理中非常重要的一环,相当于 SVN 在程序研发、运维发布中的地位。因此,一个稳定、可靠的容器仓库尤为重要。
目前我知道的的数据仓库有
Docker 官方的 Registry 原生仓库
SuSE 团队推出的出的 Portus:https://github.com/SUSE/Portus
VMWare 中国团队推出的企业级仓库—Harbor
大家熟知的 Maven 私服:Sonatype Nexus3
本文主要介绍下 Sonatype Nexus 3 这个功能强大的产品,它不仅能够用于创建 Maven 私服,还可以用来创建 yum、pypi、npm、nuget、rubygems 等各种私有仓库。而且,Nexus 从 3.0 版本也开始支持创建 Docker 镜像仓库了!
因此,在上述几个产品里面我毫不犹豫的选择了 Nexus3 作为部门的公共数据仓库,一举多得。
创建docker-compose.yaml
1 | version: "3.7" |
然后一键部署
1 | docker-compose --compatibility up -d |
大概 2 分钟左右可以完成启动,此时可以通过浏览器访问 http://IP 地址:8081 即可出现 nexus 的 web 界面:

默认账户名admin, 密码参阅官方文档, 在./data/admin.password这个文件中
1 | Default user is admin and the uniquely generated password can be found in the admin.password file inside the volume. See Persistent Data for information about the volume. |
回到前面的 repository 界面,点击 repositories 打开页面后点击【create repository】打开仓库类型选择界面
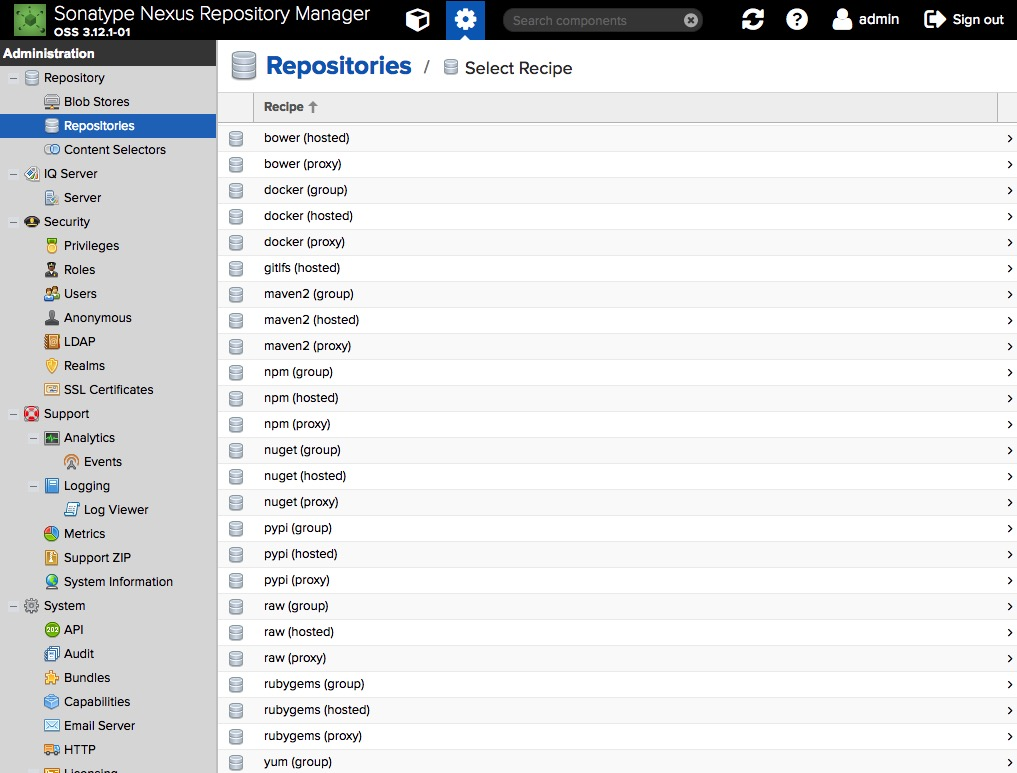
可以看到 Docker 有三种类型,分别是 docker(group),docker(hosted),docker(proxy)。其含义解释如下:
hosted : 本地存储,即同 docker 官方仓库一样提供本地私服功能
proxy : 提供代理其他仓库的类型,如 docker 中央仓库
group : 组类型,实质作用是组合多个仓库为一个地址
开始创建 Docker 仓库
首先,我们创建一个 docker 代理仓库,点击 docker(proxy),如图填写信息

往下翻页,勾上 “Allow clients to use the V1 API to interact with this Repository”,允许 Docker V1 API 请求。
至于代理的对象,我可以选择官方的镜像地址:https://registry-1.docker.io,但是官方的比较慢,所以这里我们可以填写国内的 Docker 镜像加速器地址,比如阿里云或DaoCloud的容器加速
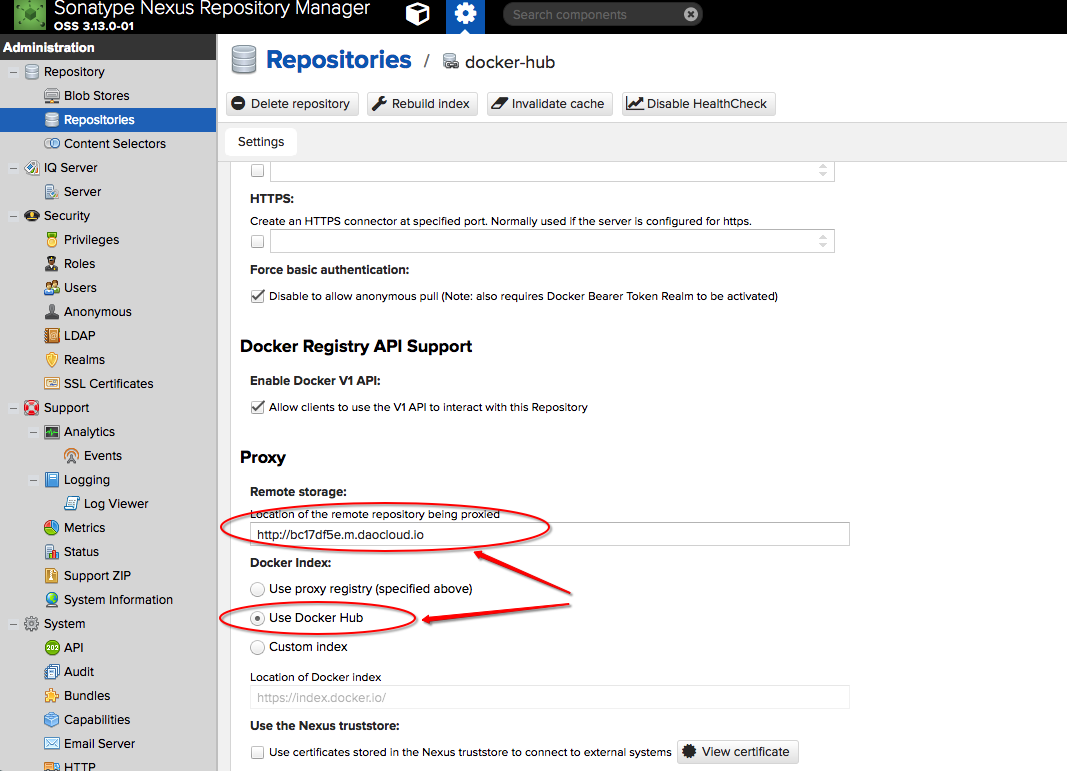
我这里选择了 DaoCloud 的镜像加速,这里为了确保能够拉取 DockerHub 最新的镜像,我选择了 Use DockerHub 这个 Index
接着,再创建一个本地仓库,这里比较简单,只需要填写本地仓库的名称,比如 docker-hosted,然后填写 HTTP 端口即可,比如 8083
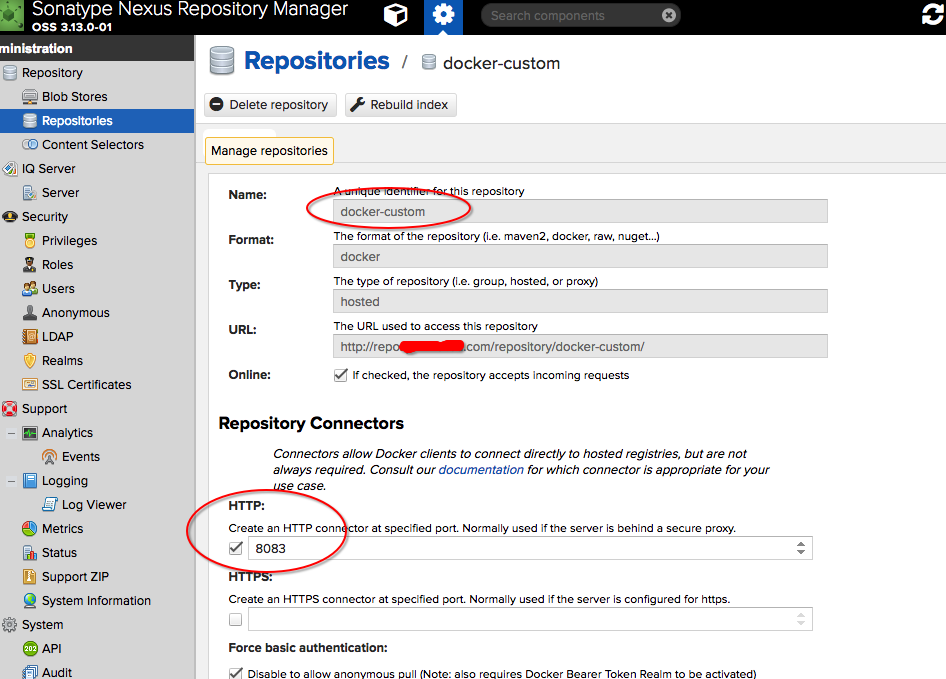
保存之后,最后创建一个聚合仓库(group),将代理仓库和本地仓库聚合到一起使用,这里我命名为 docker,然后端口选择 8082
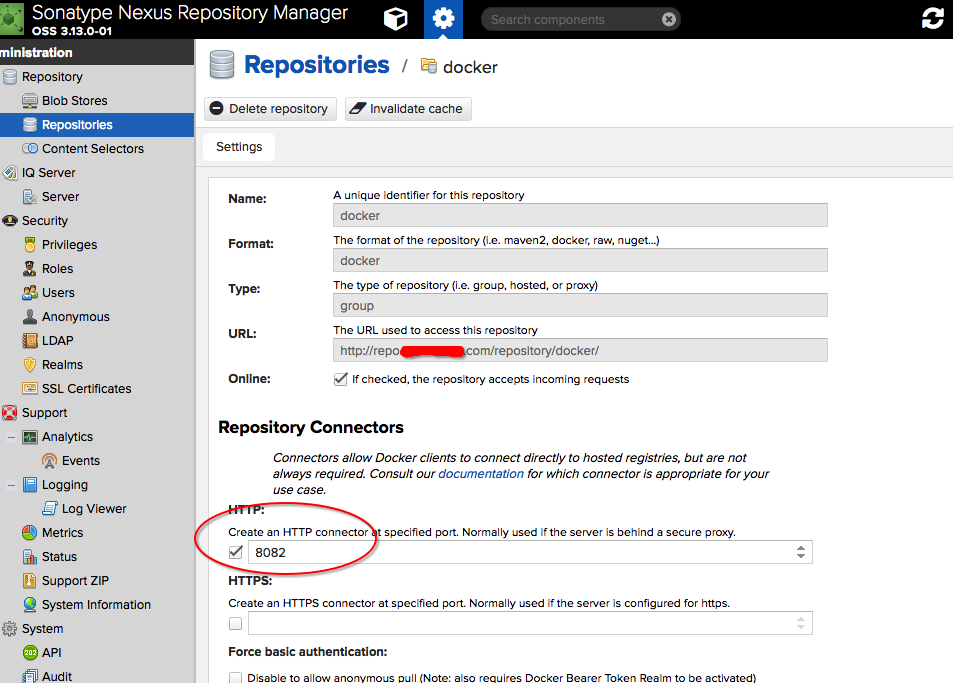
这里成员仓库的顺序可以稍微规划下,一般来说将本地的放前面,代理第三方的放后面,好处就是优先使用本地或小众的镜像仓库。我这边是用了多个第三方仓库,所有有多个

至此,nexus 在 docker 这一块是部署已经完成了,但是这样并不能很好的使用。因为 group 仓库并不能推送镜像,因为你推送自己制作的镜像到仓库还得通过本地仓库的端口去推送,很不方便!
上面配置完了,但是不够完美。
Pull/Push 操作的端口并不相同,我们需要聚合到一个端口, 通过配置 Nginx 匹配请求方法,路径的匹配来分流到不同的端口
我们需要两个域名,一个用作Nexus, 一个用作Docker
例如
nexus.abc.com
docker.abc.com
注意替换里面的IP地址
1 | upstream nexus_web { |
然后再Push镜像的时候只需要把tag加上自己域名即可
例如把官方的nginx推送到自建的仓库
1 | docker pull nginx |
改标签
1 | docker tag nginx docker.abc.com/nginx |
登录 docker.abc.com
1 | docker login docker.abc.com |
推送
1 | docker push docker.abc.com/nginx |
在launch.json文件里关闭justMyCode
1 | { |
1 | class A(object): |
上面的代码在IDE里会报错, 因为类B在声明前被引用了
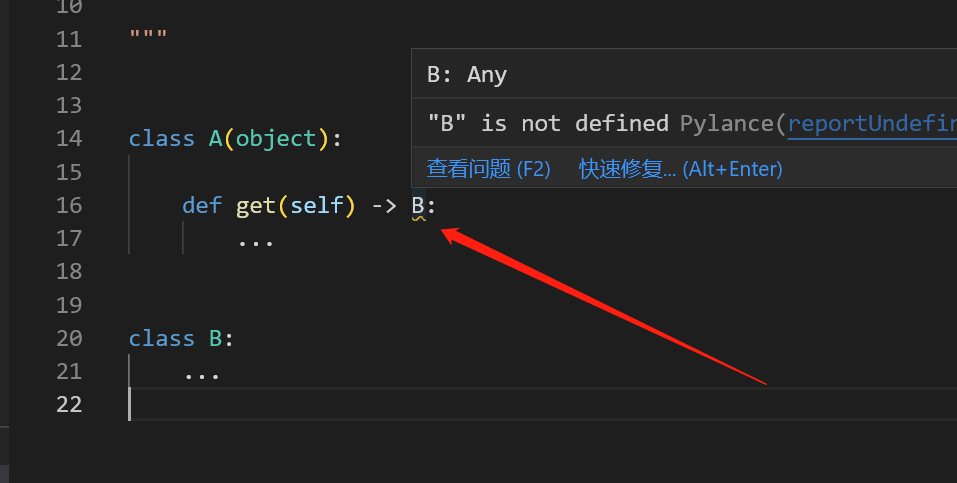
这样我们就无法利用IDE来查看类B的成员变量, 方法等内容.
解决方法很简单
1 | class A(object): |
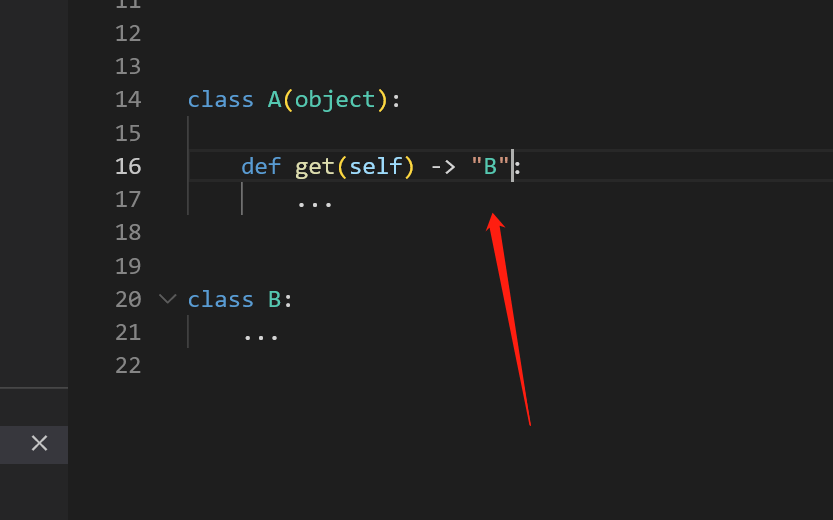
加个引号"
https://docs.python.org/zh-cn/3/library/typing.html#constant